이 문서는 V8 엔진뿐만 아니라 모든 JavaScript 엔진에 공통으로 적용되는 몇 가지 핵심 기본 사항을 설명합니다. JavaScript 개발자로서, JavaScript 엔진이 어떻게 작동하는지에 대한 이해를 통해 코드의 성능 특성을 추론할 수 있습니다.
이 포스트는 JavaScript engine fundamentals: Shapes and Inline Caches 의 글을 번역한 것입니다.
Note : 문서를 읽는 것보다 발표를 보는 것을 더 좋아한다면 아래의 동영상을 보십시오. 그렇지 않다면 문서를 계속해서 읽어 주십시오.
The JavaScript engine pipeline
모든 것은 작성된 JavaScript code로부터 시작합니다. JavaScript 엔진은 소스 코드를 구문 분석(parse)하여 AST(Abstract Syntax Tree)로 변환합니다. Interpreter는 이 AST를 기반으로 일을 시작하고 바이트 코드를 생산할 수 있습니다. 그 시점에서 엔진은 실제로 JavaScript 코드를 실행하고 있습니다.
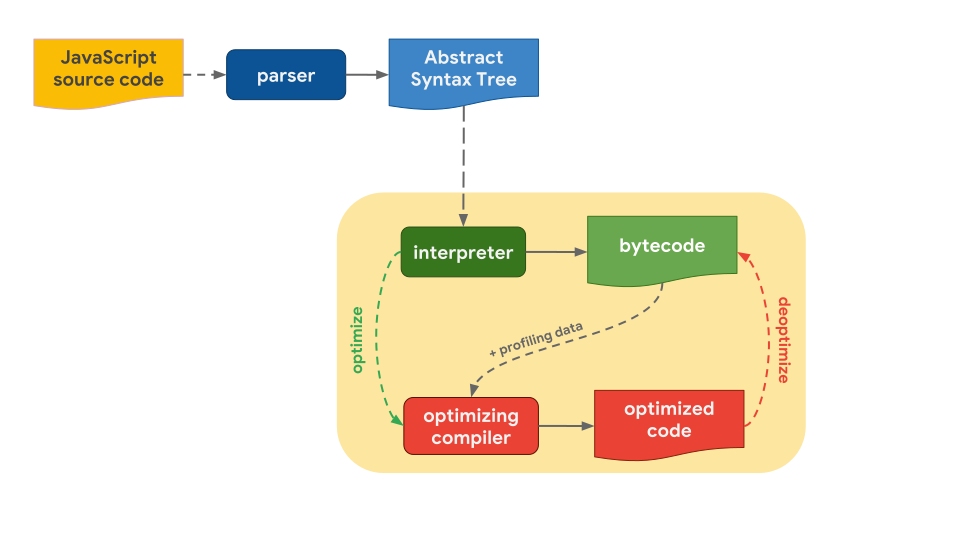
위의 과정이 더 빨리 실행되도록 하기 위해, bytecode는 profiling data와 함께 optimizing compiler로 보내집니다. optimizing compiler는 자신이 보유한 profiling data를 기반으로 특정한 가정을 한 다음 고도로 최적화된 시스템 코드(optimized code)를 생성합니다.
어느 시점에서 가정 중 하나가 잘못된 것으로 판명될 경우, optimizing compiler는 최적화를 수행하지 않고 다시 interpreter로 돌아가게 됩니다.
Interpreter/compiler pipelines in JavaScript engines
이제 JavaScript 코드를 실제로 실행하는 pipeline의 부분(즉, 코드가 해석되고 최적화되는 부분)을 파고들어 주요 JavaScript 엔진 간의 차이점 몇 가지를 살펴보겠습니다.
일반적인 경우를 말해보자면, interpreter와 optimazing compiler가 들어 있는 pipeline이 있습니다. 아래의 그림과 함께 살펴보겠습니다. Interpreter는 최적화되지 않은 bytecode를 빠르게 생성하며, optimazing compiler는 시간이 좀 더 걸리지만 결국 고도로 최적화된 머신 코드(optimized code)를 생성합니다.
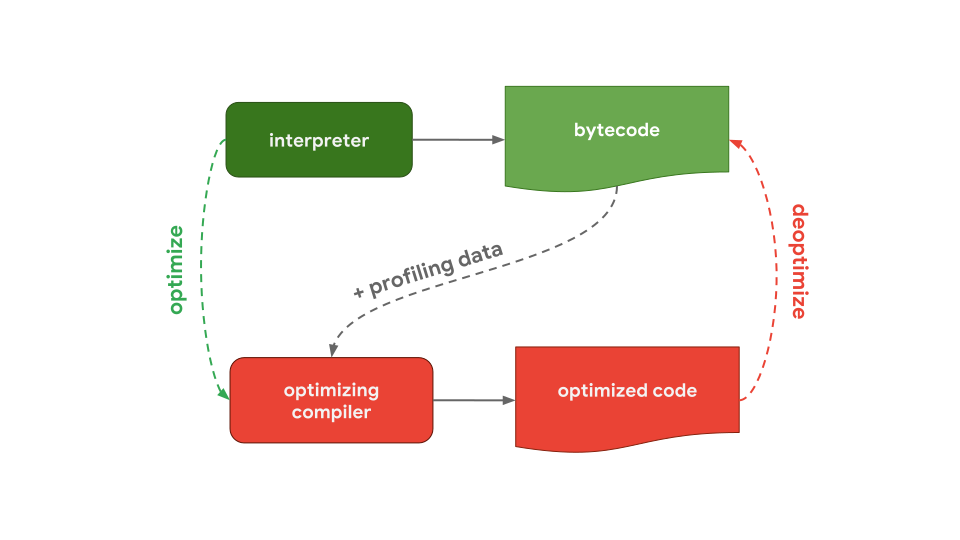
아래 그림의 pipeline이 작동하는 방식은 Chrome 및 Node.js에서 사용되는 JavaScript 엔진이 작동하는 방식과 거의 동일합니다.
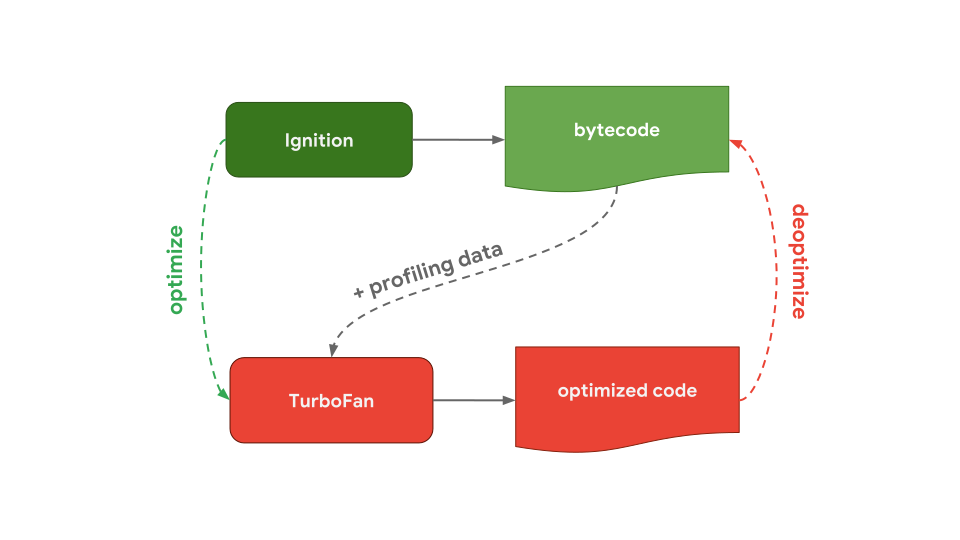
V8의 interpreter는 Ignition이라고 불리며, bytecode를 생성하고 실행하는 역할을 합니다. Bytecode를 실행하는 동안, 이후에 실행 속도를 높이는데 사용하기 위해서 profiling data를 수집합니다. 예를 들어, 종종(often) 실행되는 기능에 부하가 걸리면, 생성된 bytecode와 profiling data는 TurboFan(최적화된 컴파일러)으로 전달되어 profiling data를 기반으로 최적화 머신 코드(optimized code)를 생성합니다.
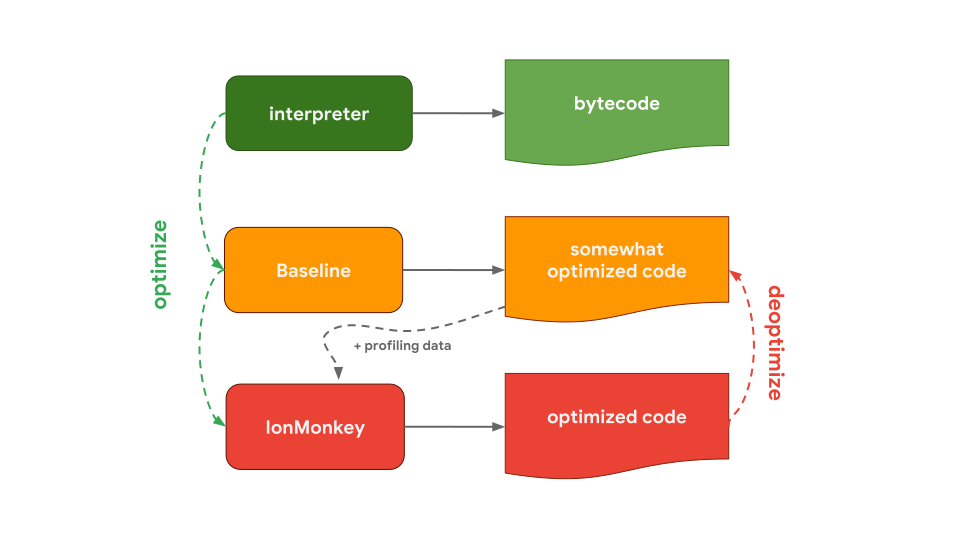
FireFox와 SpiderNode 에서 사용되는 Mozilla의 JavaScript 엔진인 SpiderMonkey는 조금 다른 방식을 사용합니다. SpiderMonkey는 하나가 아닌 두 개의 optimizing compiler를 가지고 있습니다. Interpreter는 somewhat optimized code(다소 최적화된 code)를 생산하는 Baseline compiler로 최적화를 수행합니다. IonMonkey 컴파일러는 profiling data(코드를 실행하는 동안 수집됨)와 결합하여 optimized code를 생성합니다. 투기적(speculative) 최적화에 실패하면 IonMonkey는 Baseline 코드로 되돌아간다.
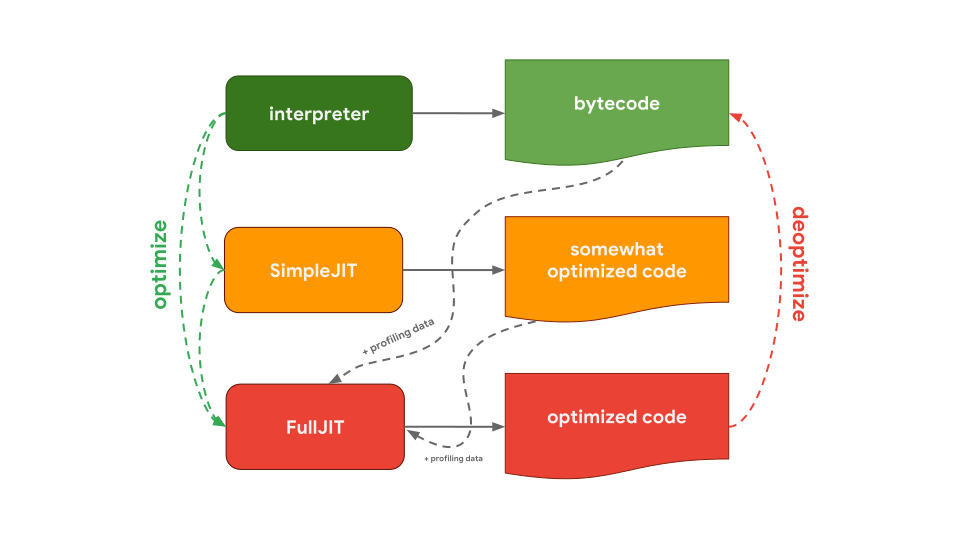
Edge 및 Node-ChakraCore에서 사용되는 Microsoft의 JavaScript 엔진인 Chakra는 앞서 보여드린 두 최적화 컴파일러와 매우 유사한 설정을 가지고 있습니다. Interpreter는 somewhat optimized code를 생성하는 SimpleJIT(Just-In-Time)로 optimized됩니다. Profiling data와 결합된 FullJIT는 보다 효율적으로 optimized code를 생성할 수 있습니다.
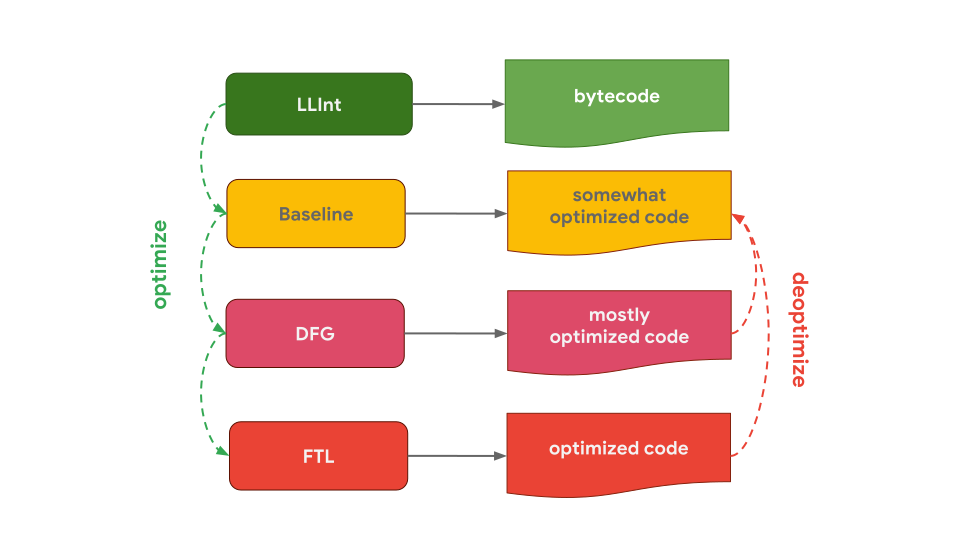
JavaScriptCore(JSC로 약칭)는 Safari 및 React Native에서 사용되는 Apple의 JavaScript 엔진으로, 세 가지 최적화 컴파일러를 극단적으로 사용합니다. LLInt(Low-Level Interpreter)는 Baseline compiler로 최적화되며, Baseline 컴파일러는 DFG(Data Flow Graph) 컴파일러로 최적화고, DFG 컴파일러는 FTL(Faster Than Light) 컴파일러로 최적화됩니다.
왜 어떤 엔진들은 다른 엔진들보다 더 최적화된 컴파일러를 가지고 있을까요? 모든 것은 타협(trade-offs)이라고 볼 수 있습니다. Interpreter는 빨리 bytecode를 만들 수 있지만, 일반적으로 bytecode는 그리 효율적이지 않습다. 반면에 최적화 컴파일러는 시간이 좀 더 걸리지만 결국 훨씬 더 효율적인 machine code를 만들어냅니다. 빨리 코드를 실행하거나(Interpreter) 더 많은 시간을 들일 수 있지만 결국 최적의 성능(컴파일러 최적화)으로 코드를 실행할 수 있습니다. 일부 엔진은 시간/효율의 특성이 다른 여러 개의 최적화 컴파일러를 추가함으로써 “복잡성이 가중되는 비용(the cost of additional complexity)” 과 “보다 세밀하게 제어(more fine-grained control)”사이의 타협(trade-offs)를 결정할 수 있습니다.
각 JavaScript 엔진에 대해 interpreter와 컴파일러 pipeline 최적화의 주요 차이점을 강조하여 살펴보았습니다. 그러나 이러한 차이점 외에도, high-level에서 보면 모든 JavaScript 엔진은 동일한 아키텍처(Parser와 일종의 interpreter/compiline pipeline)를 가지고 있습니다.
JavaScript’s object model
이제 일부 사항들이 구현되는 방법을 파고들어 JavaScript 엔진의 공통점을 살펴보겠습니다.
예를 들어 JavaScript 엔진은 어떻게 JavaScript object model을 구현하고, JavaScript object의 property에 접근하는 속도를 높이기 위해 어떤 기술을 사용할까요? 밝혀진 바와 같이, 모든 주요 엔진들은 이것들을 매우 유사하게 구현합니다.
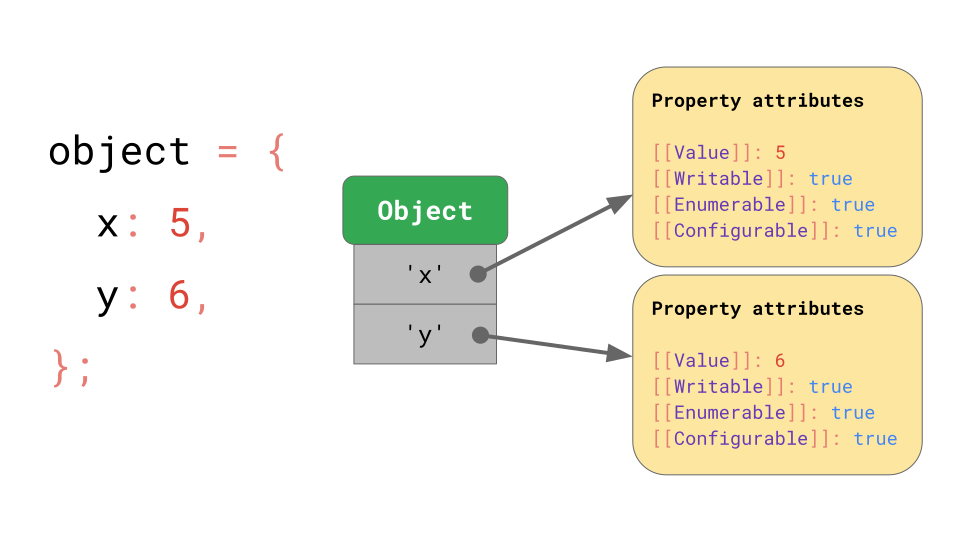
ECMAScript 규격은 기본적으로 모든 object를 사전(property attributes에 문자열로 매핑)으로 정의합니다.
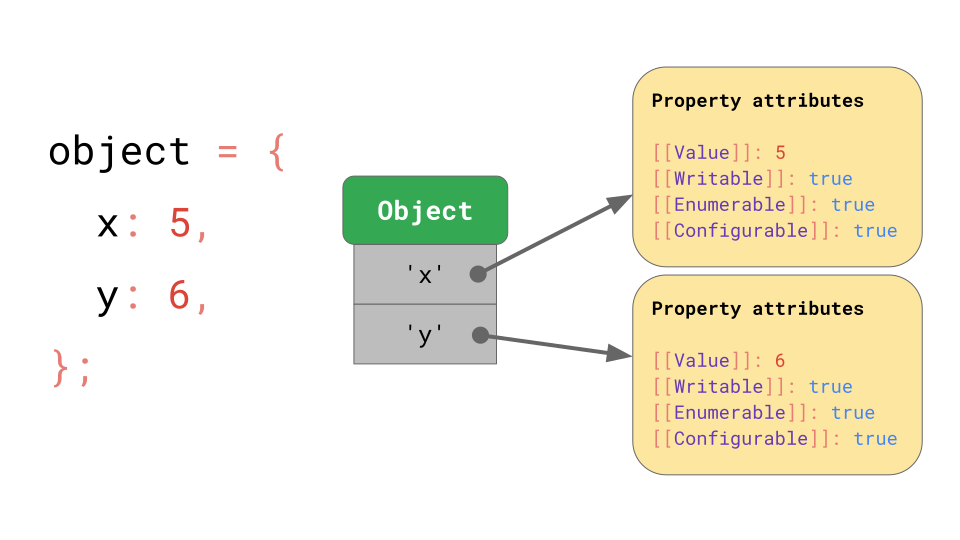
규격(spec)은 object 자신의 [[value]] 를 제외하더라도, 다른 property들을 가진다는 것을 알려줍니다.
- [[Writable]] : 재할당할 수 있는지 여부를 결정합니다.
- [[Enumerable]] : for…in 루프에서 열거될 수 있는지를 나타냅니다.
- [[Configurable]] : property를 삭제할 수 있는지 여부를 결정합니다.
[[double square brakets]] 표기법은 우스꽝스러워 보이지만, spec에서 JavaScript이 직접적으로 노출하지 않는 property를 나타내는 방법입니다. Object.getOwnPropertyDescriptor API를 사용하여 JavaScript에서 지정된 object 및 property에 대한 다음과 같은 property attribute 들을 가져올 수 있습니다.
const object = { foo: 42 };
Object.getOwnPropertyDescriptor(object, 'foo');
// → { value: 42, writable: true, enumerable: true, configurable: true }
자, 이것이 JavaScript가 object를 정의하는 방법입니다. Array는 어떨까요?
Array를 object의 특별한 case라고 생각할 수 있습니다. 한 가지 차이점은 array가 array index들을 특별히 처리한다는 것입니다. 여기서 말하는 array index는 ECMAScript 규격의 특수 용어입니다. JavaScript에서 array의 길이는 최대 232-1 개로 제한됩니다. Array index는 이 길이 내에서는 모두 유효합니다. 즉, 0 ~ 232-2 사이의 정수를 뜻합니다.
또 다른 차이점은 array에도 마법과 같은 length 라는 property가 있다는 것입니다.
const array = ['a', 'b'];
array.length; // → 2
array[2] = 'c';
array.length; // → 3
위의 코드를 보면, array가 생성될 때는 length가 2였습니다. 그 후, index 2에 다른 값을 할당하였더니 length가 자동으로 변경되었습니다.
JavaScript는 array를 object와 유사하게 정의합니다. 예를 들어 array index를 포함한 모든 키는 문자열로 명시적(explicitly)으로 표시됩니다. Array의 첫 번째 요소는 키 '0' 아래에 저장됩니다.
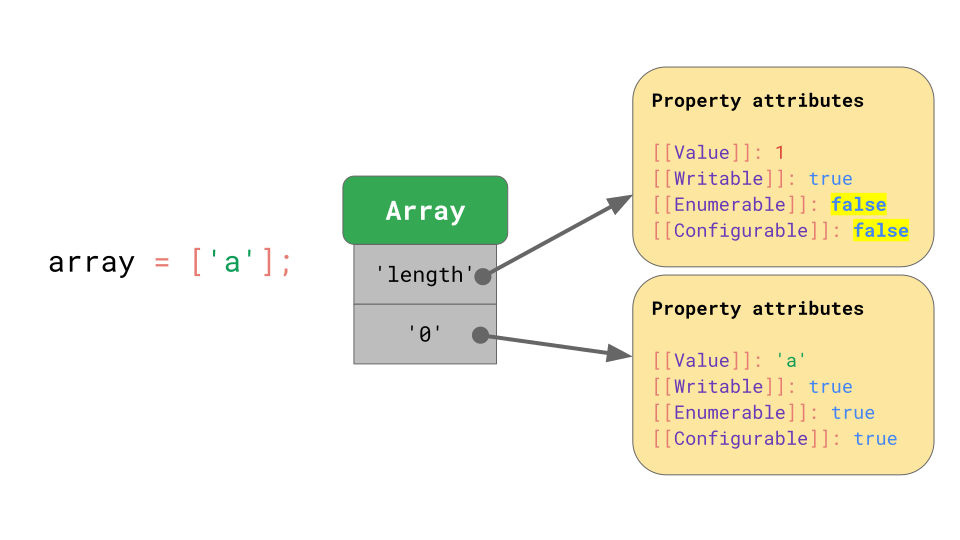
'length' property는 열거할 수 없고, 삭제할 수 없는 다른 property입니다.
Array에 항목이 하나 추가되면, JavaScript는 'length' property의 attributes중 하나인 [[value]] 값을 자동으로 갱신합니다.
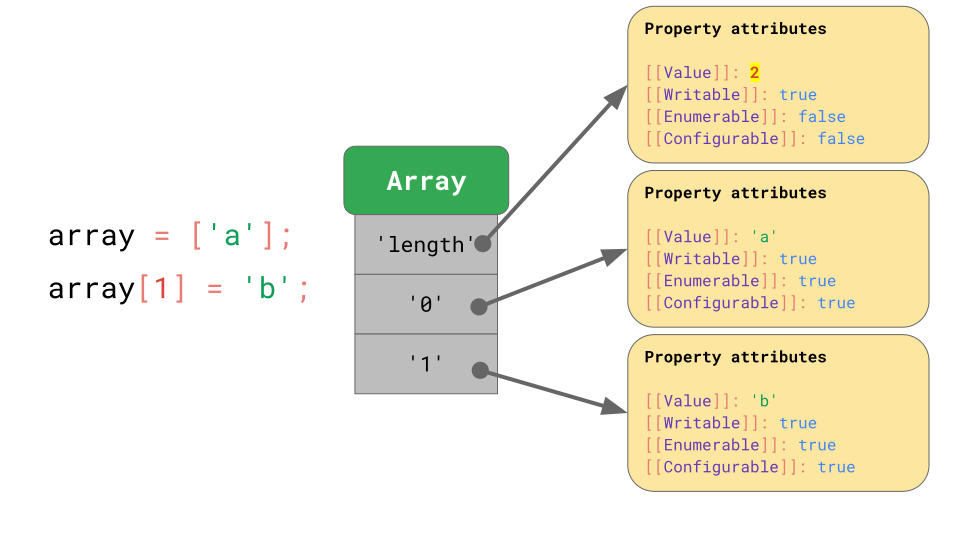
일반적으로, array는 object와 비슷하게 작동합니다. :)
Optimizing property access
우리는 object가 JavaScript에서 어떻게 정의되었는지를 알았습니다. 이제 JavaScript 엔진이 object를 효율적으로 사용하여 작업하는 방법에 대해 알아보겠습니다.
주위의 JavaScript 프로그램들을 살펴보면, property에 접근하는 것이 가장 일반적인 작업입니다. 그러므로 JavaScript 엔진이 property에 빠르게 액세스 하는 것이 중요해집니다.
const object = {
foo: 'bar',
baz: 'qux',
};
// Here, we’re accessing the property `foo` on `object`:
doSomething(object.foo);
// ^^^^^^^^^^
Shapes
JavaScript 프로그램에서, 아래의 코드와 같이, 같은 property key들을 가지는 여러 개의 object를 사용하는 것이 일반적입니다. 이러한 object들은 같은 shape 가 같다고 말합니다.
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
// `object1` and `object2` have the same shape.
그리고 아래의 코드와 같이, 동일한 shape의 object에서 동일한 property에 접근하는 것 또한 매우 일반적입니다.
function logX(object) {
console.log(object.x);
// ^^^^^^^^
}
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);
이러한 점들을 염두에 두고, JavaScript 엔진은 object shape에 따라 object property에 접근하는 것을 최적화할 수 있습니다. 최적화 하는 방법은 다음과 같습니다.
x와 y property를 가진 object가 있다고 가정해 보겠습니다. 앞에서 설명한 사전 데이터 구조(Key는 문자열로서 포함되고, 각각의 property attribute들을 가리킵니다)를 사용합니다.
object.y에 접근한다고 할 때, JavaScript 엔진은 JSObject에서 key 'y'를 찾아 해당 property attribute들을 로드한 후 [[Value]]를 반환합니다.
하지만 이러한 property attribute는 메모리의 어느곳에 저장될까요? 그것들을 JSObject의 일부로 저장해야 할까요? 나중에 이 shape의 object를 더 사용하게 될 것이라고 가정하면, property 이름이 동일한 object가 반복되므로, property 이름과 attribute를 포함하는 전체 사전을 JSObject 자체에 저장하는 것은 낭비가 됩니다. 이러한 것은 중복이 많아지고 불필요하게 메모리를 사용하게 됩니다. 그러므로 최적화로서, JavaScript 엔진은 object의 shape를 별도로 저장합니다.
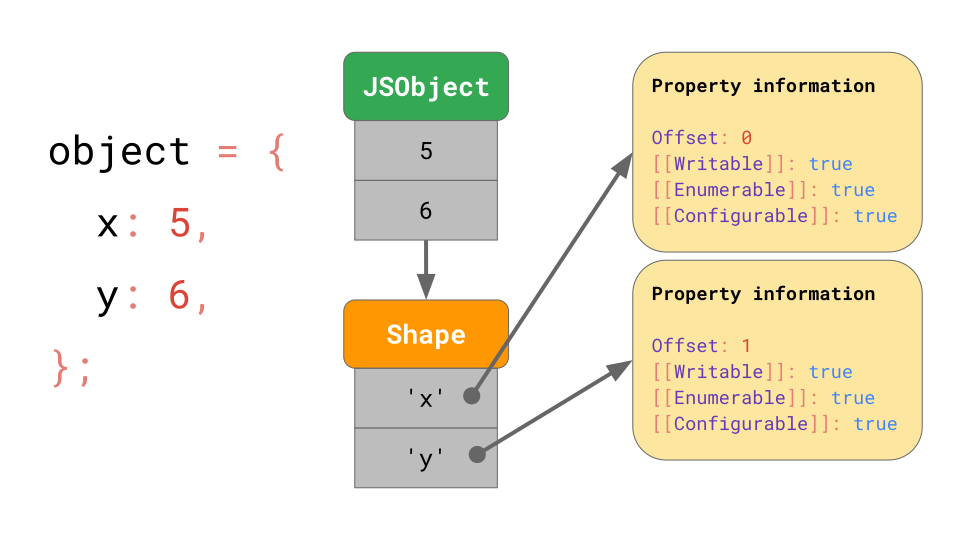
아래의 그림에서, 이 Shape는 [[Value]]들을 제외한 모든 property 이름과 attribute들을 포함합니다. 대신 Shape는 JSObject에 있는 value의 offset 값을 가지고 있어서, JavaScript 엔진이 value의 위치를 알 수 있습니다. 같은 shape를 가진 모든 JSObject는 같은 Shape instance를 정확히 가리킵니다(point). 이제 모든 JSObject는 이 object에 고유한 value만 저장하면 됩니다.
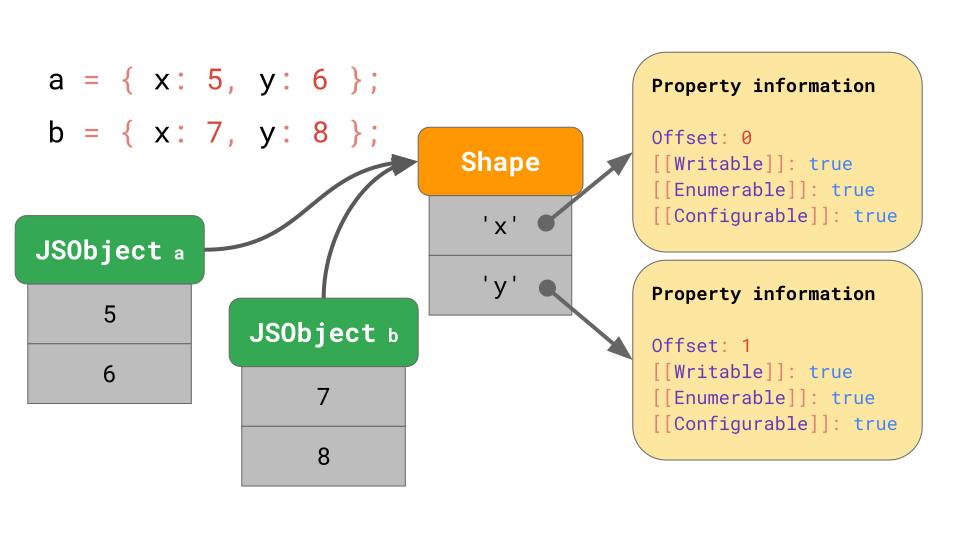
여러 개의 object를 사용할 때 장점이 더 명확하게 나타납니다. 얼마나 많은 object가 있든 간에, 같은 shape가 있는 한, shape와 property 정보를 한 번만 저장하면 됩니다.
모든 JavaScript 엔진은 shape를 최적화에 사용하지만, 모두 그것을 shape이라고 부르지는 않습니다.
- 학술 논문에서는 이를 Hidden Classes 라고 합니다.(JavaScript class와 혼동)
- V8은 이러한 Map 이라고 부릅니다.(JavaScript의 Map과 혼동)
- Chakra는 이를 Types 라고 합니다.(JavaScript의 dynamic types, typeof와 혼동)
- JavaScriptCore에서는 Structures 라고 합니다.
- SpiderMonkey는 Shapes 라고 부른다.
이 문서 전반에 걸쳐 ‘Shapes’라는 용어를 계속 사용하겠습니다.
Transition chains and trees
특정 shape를 가지고 있는 object에 property를 추가하면 어떤 일이 생길까요? JavaScript 엔진은 새로운 shape를 어떻게 찾을까요?
const object = {};
object.x = 5;
object.y = 6;
JavaScript 엔진에서 shape는 transition chain을 형성합니다. 아래의 그림을 예로 살펴보겠습니다.
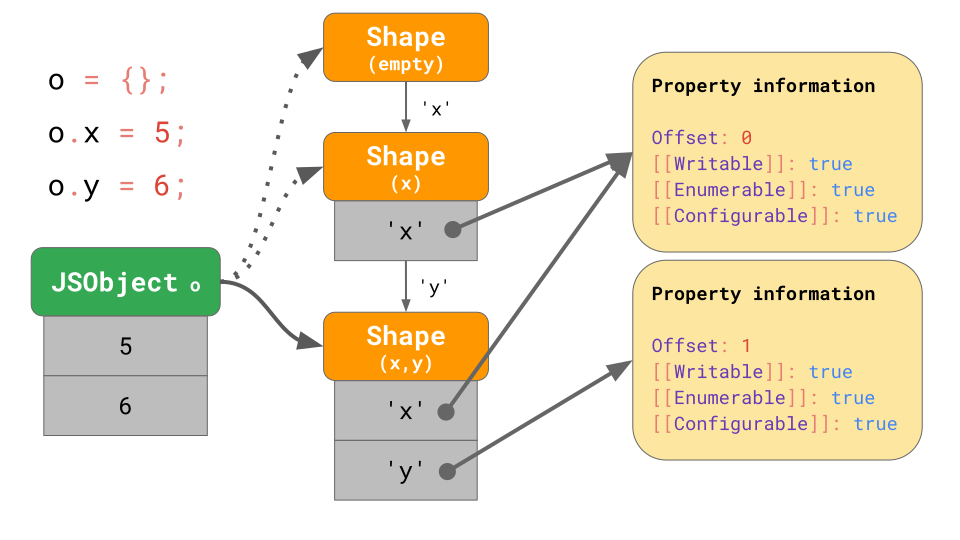
Object는 아무 property가 없이 시작하기 때문에 빈 shape를 가리킵니다. 다음 명령문으로 object에 값이 5인 property 'x'를 추가함으로서, JavaScript 엔진이 shape에 'x' property를 추가하고 JSObject의 첫 번째 offset인 0에 value 5를 추가합니다. 다음 명령문으로 property 'y'를 추가하면, JavaScript 엔진은 shape를 'x', 'y'가 모두 포함도록 변환합니다. 그리고 JSObject에 6을 추가합니다(offset은 1).
Note : property가 추가된 순서는 shape에 영향을 줍니다. 예를 들어, { x: 4, y: 5 }의 경우와 { y: 5, x: 4 }의 경우는 shape이 달라집니다.
각 Shape에 대한 전체 property table도 저장할 필요가 없습니다. 대신, 모든 Shape은 새로 포함한 property에 대한 것만 필요합니다. 아래의 그림을 예로 들어보겠습니다. 'x'에 대한 정보는 chain에 연결된 바로 앞의 shape에 있기 때문에, 마지막 shape에는 저장할 필요가 없습니다. 이게 가능하기 위해서는 모든 Shape는 이전 shape와 연결되어 있어야 합니다.
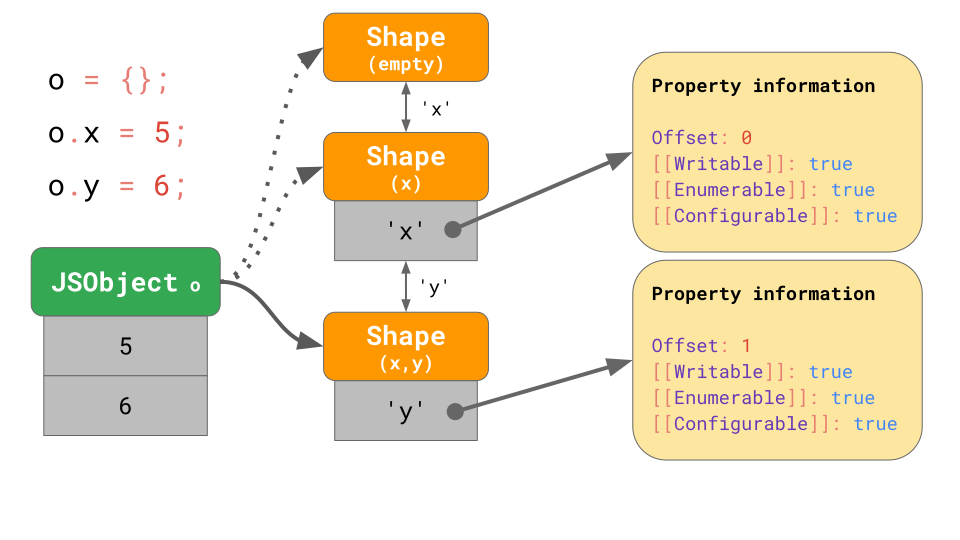
JavaScript 코드에서 o.x에 값을 입력하게 되면, JavaScript 엔진은 'x'가 포함된 Shape를 찾기위해 transition chain을 아래에서 위로 탐색합니다.
Transition chain을 만들 수 없다면 어떻게 될까요? 예를들어, 아래의 코드와 같이 2개의 빈 object를 만들고 각자 다른 property를 추가한다면 어떻게 될까요?
const object1 = {};
object1.x = 5;
const object2 = {};
object2.y = 6;
이런 경우에는 chain 대신 branch를 사용해서 transition tree 를 사용해야 합니다.
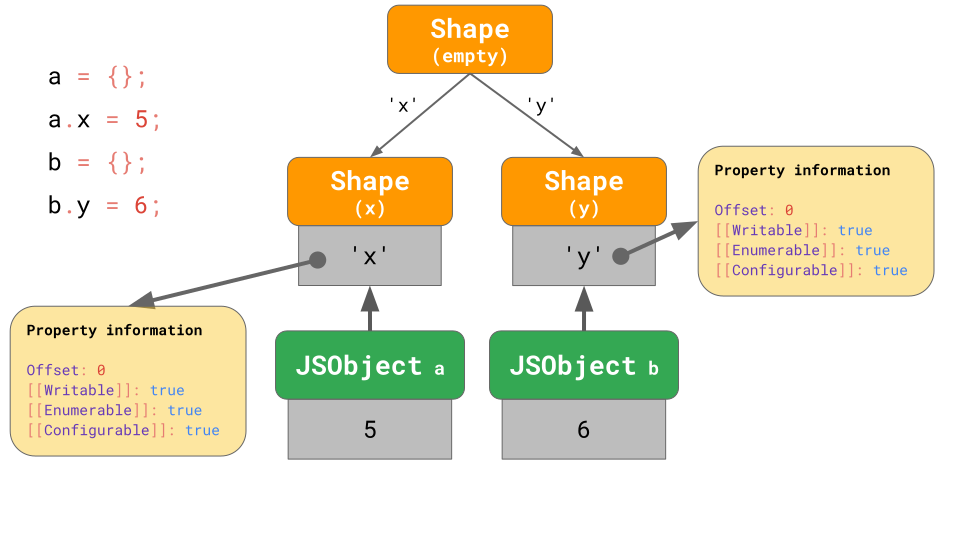
위의 그림을 보겠습니다. a라는 빈 object를 만든 후 'x'라는 property를 추가하였습니다. 이때는 하나의 값만 가지는 JSObject와 2개의 Shape만 생성됩니다. (비어있는 shape와 x property만 가지는 shape)
두 번째로, b라는 빈 object가 생성되고 'y'라는 또 다른 property를 추가합니다. 결과적으로 2개의 shape chain이 생성되고 3개의 shape가 생성됩니다.
위의 예제를 봤을 때, 항상 빈 shape로 시작되는 걸까요? 꼭 그렇다고는 할 수 없습니다. 엔진은 처음부터 property를 포함하는 object literal 에 대한 초기화도 적용하고 있습니다. 아래의 코드와 같이, 빈 object literal 에 x property를 추가할때와 처음부터 x property를 추가한 object literal을 살펴보겠습니다.
const object1 = {};
object1.x = 5;
const object2 = { x: 6 };
위 코드에서 첫 번째 라인은, 빈 shape에서 시작해서 x가 추가된 shape로 transition하게 됩니다. 이는 우리가 이전에 살펴본 것과 같습니다.
object2의 경우에는, 빈 shape에서 transition 하는 것 보다 처음부터 이미 x가 포함된 shape를 생성하는 것이 상식적입니다.
'x' property를 포함하는 object literal은 처음부터 'x'가 포함된 shape에서 시작하여 빈 shape를 효과적으로 사용하지 않습니다. 이러한 방법들을 적어도 V8과 Spider Monkey에서 사용하고 있습니다. 이러한 최적화는 transition chain을 단축하고 literal에서 object를 보다 효율적으로 생성할 수 있도록 합니다.
Benedikt blog의 post인 surprising polymorphism in React applications 는 이러한 세부 요소들이 실제 성능에 어떻게 영향을 미칠 수 있는지에 대해서 이야기합니다.
아래 코드는 'x', 'y', 그리고 'z' property들을 가지는 3D point object를 나타내고 있습니다.
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;
우리가 배우기로, 이것은 object와 함께 3개의 shape를 메모리에 생성합니다(빈 shape는 개수에 포함하지 않겠습니다). 아래의 그림과 같이 'x' property에 접근하기 위해서 program에서 point.x 를 입력한다면, JavaScript 엔진은 linked list를 따라갑니다. Shape의 제일 아래에서 시작해서, 'x'가 포함된 제일 위 Shape까지 올라갑니다.
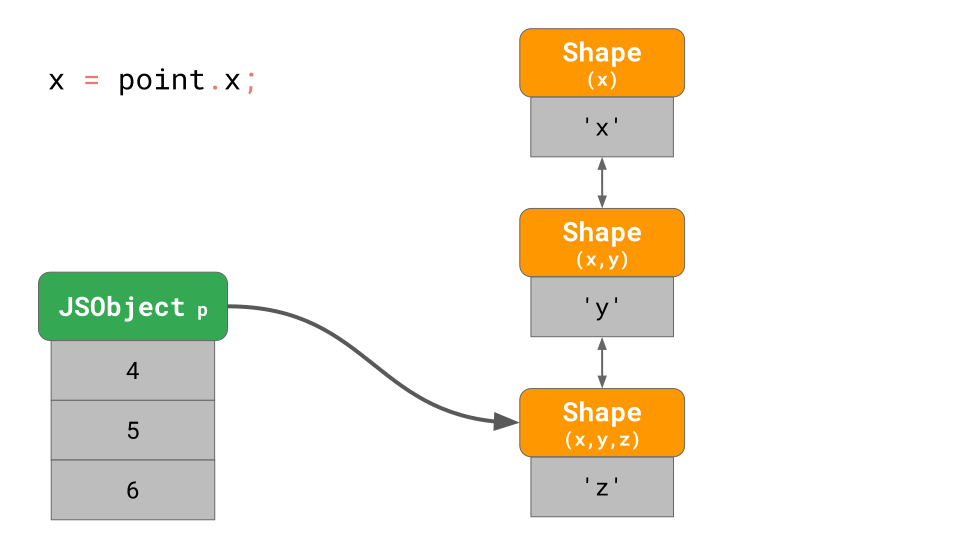
만약 우리가 이러한 작업을 더 자주 한다면, 특히 object에 많은 property가 있을 때, 정말 느려질 것입니다. Property를 찾는 시간은 O(n)입니다. 즉, object의 property 개수에서 선형(linear)입니다. Property 검색 속도를 높이기 위해 JavaScript 엔진은 ShapeTable 데이터 구조를 추가합니다. 이 ShapeTable은 지정된 property를 가지는 각 Shape에 property key를 매핑하는 사전입니다.
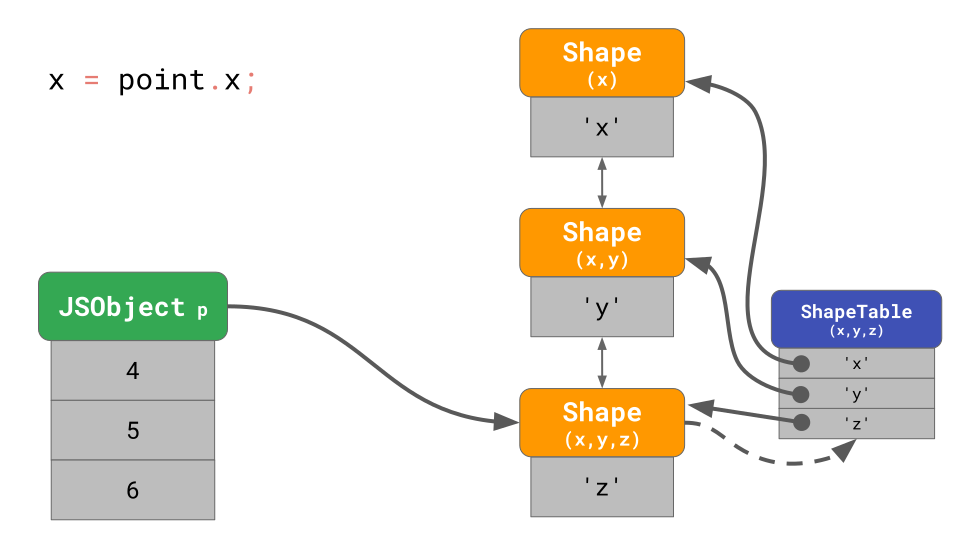
여기서 잠시 살펴보면, 우리는 사전 검색으로 돌아왔습니다… 만 애초에 Shape를 사용하기 전에 사전은 사용하고 있었습니다! 그럼 왜 우리는 Shape에 신경을 써야 할까요?
그 이유는 shape가 inline cache 라고 불리는 또 다른 최적화를 가능하게 하기 때문입니다.
Inline Caches (ICs)
Shape 를 사용하는 주된 이유는 Inline Caches(ICs)라는 개념때문입니다. ICs는 JavaScript를 신속하게 실행할 수 있게하는 핵심 요소입니다. JavaScript 엔진은 ICs를 사용하여 object에서 property를 찾을수 있는 위치에 대한 정보를 암기하여, 높은 cost를 가지는 조회 횟수를 줄입니다.
여기에, object를 받아서 그 object의 property x를 반환하는 함수 getX가 있습니다.
function getX(o) {
return o.x;
}
위의 함수를 JSC에서 실행한다면, 아래의 그림과 같은 bytecode를 생성할 것입니다.

첫 번째 명령문 get_by_id는 첫 번째 argument (arg1)에서 property 'x'를 로드하여 결과를 loc0에 저장합니다. 두 번째 명령문은 loc0에 저장한 것을 반환합니다.
또한 JSC는 get_by_id 명령문에 초기화되지 않은 두 개의 슬롯으로 구성된 Inline Cache를 포함합니다.
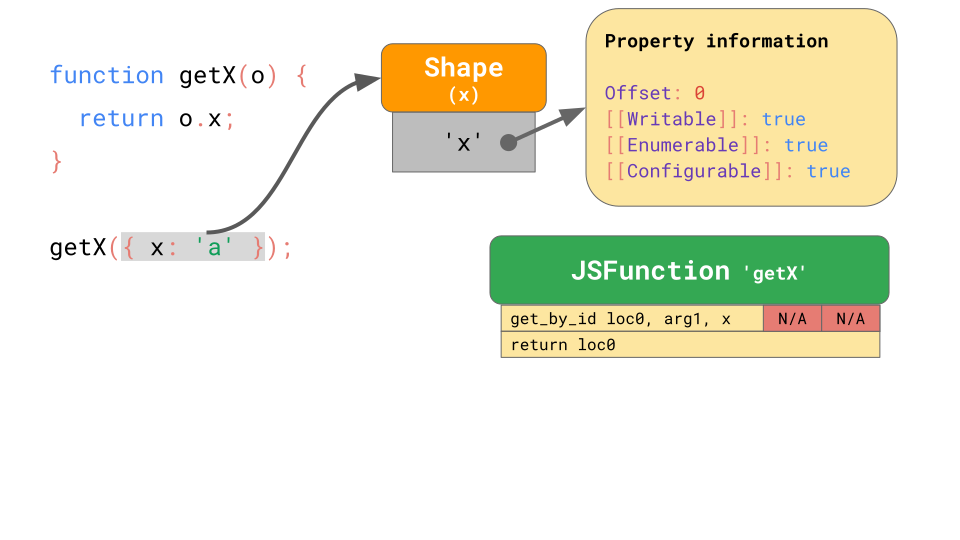
이제 위의 그림과 같이 {x: 'a'} object가 getX 함수에서 실행될 때를 보겠습니다. 앞서 배웠듯이, 이 object는 property 'x'가 있는 shape를 가지며, 이 Shape는 property x에 대한 offset과 attribute 들을 가집니다. 이 함수를 처음 실행하면, get_by_id 함수는 property 'x'를 검색하고 value는 offset 0에 저장되어 있다는 것도 찾게 됩니다.
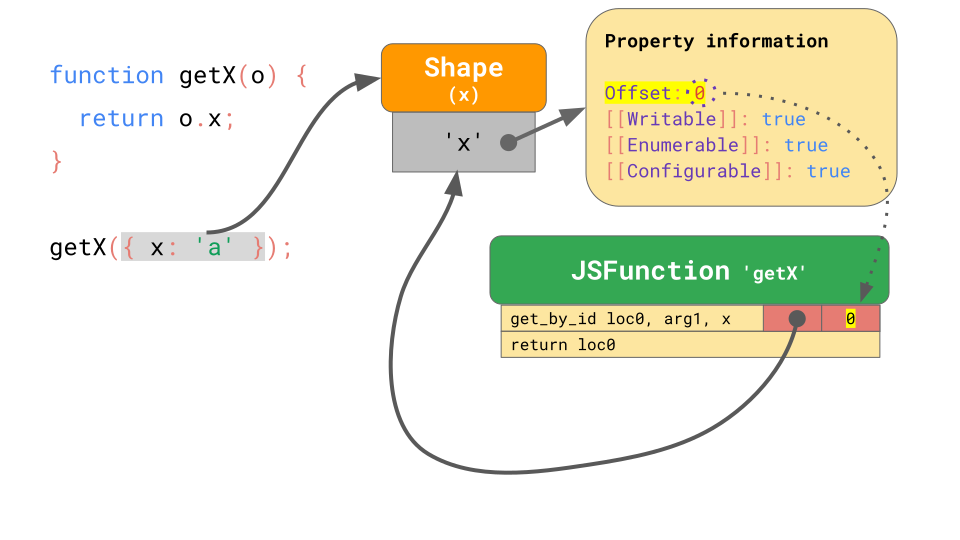
위의 그림에서 처럼 get_by_id 명령문에 포함된 IC는 property가 발견된 shape와 offset을 기억합니다.
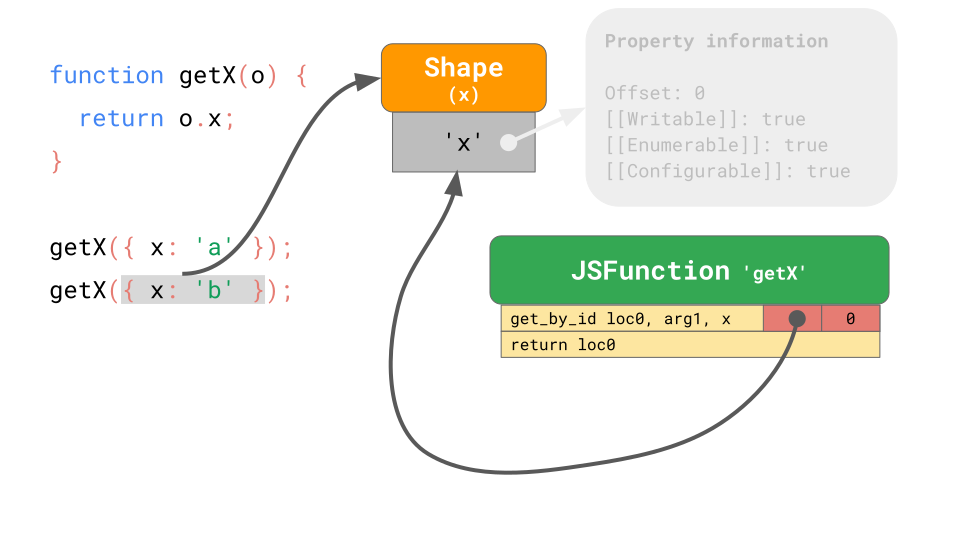
위의 그림을 살펴보겠습니다. 다음 명령문을 실행할 때, IC는 shape만 비교하면 되며, 이전과 같다면 저장되어있는 offset을 보고 value를 가져오면 됩니다. 구체적으로 말하자면, JavaScript 엔진이 IC가 이전에 기록한 shape의 object를 볼 경우, 더 이상 property 정보에 접근할 필요가 없습니다. 그리고 비용이 많이 들어가는 property 정보 조회를 완전히 생략할 수 있습니다. 이 방법은 매번 property를 조회하는 것 보다 훨씬 더 빠릅니다.
Storing arrays efficiently
Array의 경우, array의 property인 array indices 를 저장하는 것이 일반적입니다. 각 property의 값들은 array element라고 부릅니다. 모든 array의 모든array element에 대한 각각의 property attribute들을 저장하는 것은 메모리 낭비일 수 있습니다. 그 대신에, JavaScript 엔진은 array-indexed property 들이 기본적으로 writable, enumerable, 그리고 configurable하다는 점을 사용합니다. 그리고 array element를 다른 이름을 가지는 property(named property)와는 별도로 저장합니다.
다음 array를 고려해봅시다.
const array = [
'#jsconfeu',
];
아래의 그림과 같이, JavaScript 엔진은 array의 길이 (1) 을 저장하고, 'length' property에 대한 offset과 attribute들을 가지고 있는 Shape를 가리킵니다(point).
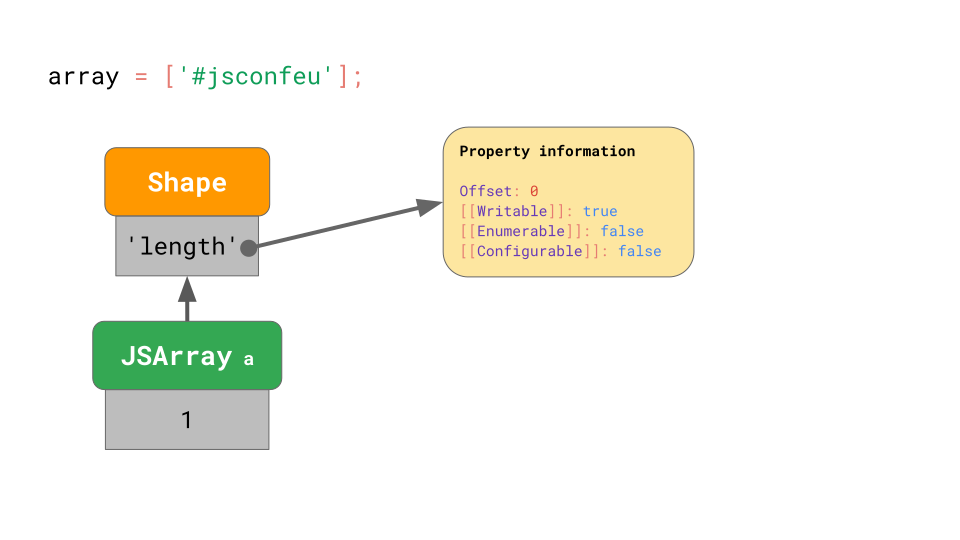
이것은 우리가 이전에 본 것과 비슷합니다… 그런데 array의 value는 어디에 저장될까요?
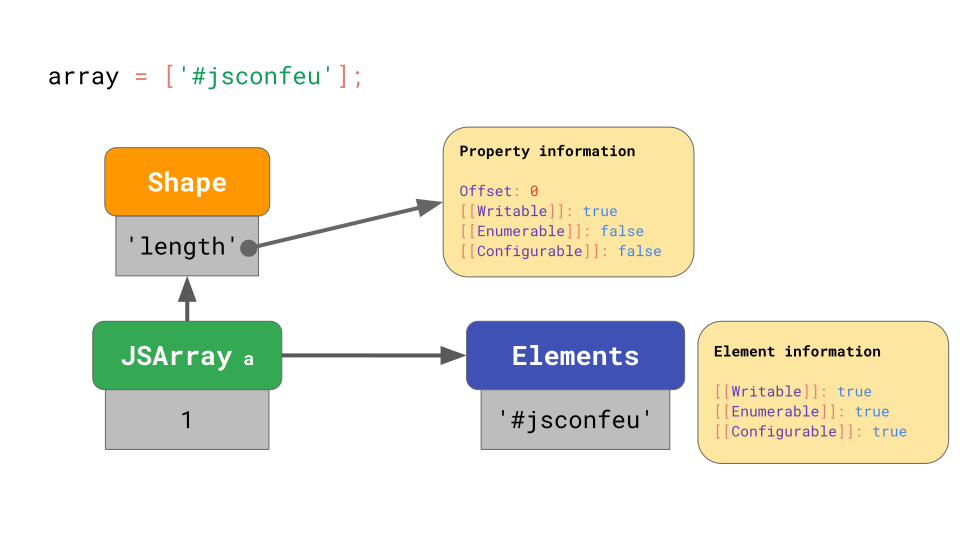
모든 array에는 array-indexed property 값이 모두 포함된 별도의 element 백업 저장소 가 있습니다. 일반적으로 모든 array element에 대한 property attribute 들은 writable, enumerable, 그리고 configurable하기 때문에 JavaScript 엔진은 그것들을 저장할 필요가 없습니다.
하지만 특이한 경우엔 어떤 일이 일어날까요? Array element의 property attribute 들을 변경하면 어떻게 될까요?
// Please don’t ever do this!
const array = Object.defineProperty(
[],
'0',
{
value: 'Oh noes!!1',
writable: false,
enumerable: false,
configurable: false,
}
);
위의 코드는 '0'이라는 property를 정의하지만(array의 index가 됨), attribute 들을 기본값과 다르게 설정합니다.
이런 특이한 경우, JavaScript 엔진은 모든 element 백업 저장소를 property attribute 들에 array index 들을 매핑하는 사전으로 나타냅니다.
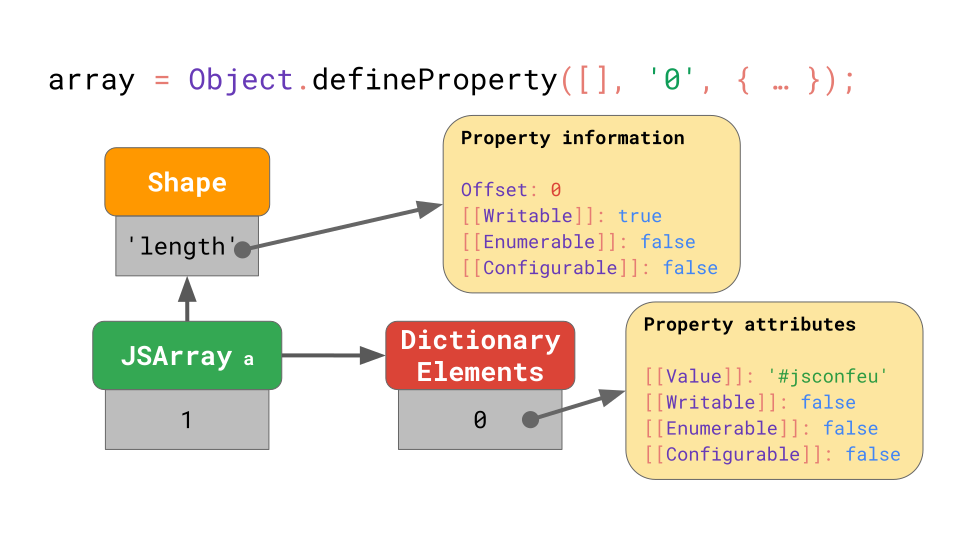
하나의 array element에 기본값이 아닌 property attribute 들이 있을때도, 전체 array의 백업 저장소가 느리고 비효율적인 모드로 전환됩니다. Array index에서 Object.defineProperty는 사용하지 마십시오. (당신이 왜 이걸 사용하려 하는지 모르겠습니다. 이상하고, 쓸모없어 보입니다.)
Take-aways
JavaScript 엔진이 object와 array를 저장하는 방법과, shape 및 ICs를 통해 일반적인 작업을 최적화하는 방법을 배웠습니다. 이러한 지식을 바탕으로 성능을 향상시킬 수 있는 몇 가지 실용적인 JavaScript 코딩 팁을 확인했습니다.
- 항상 동일한 방식으로 object를 초기화하여 shape가 서로 다르지 않게 합니다.
- 효율적으로 저장 및 작동할 수 있도록 array element의 property attribute 들을 건드리지 마십시오.